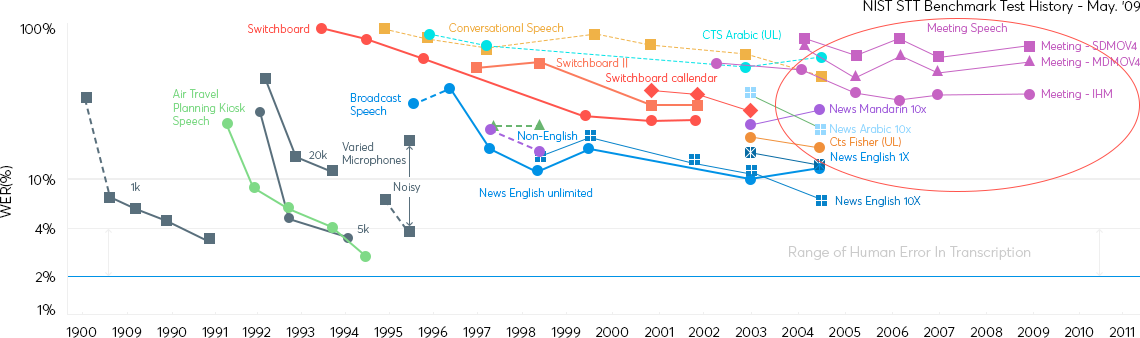
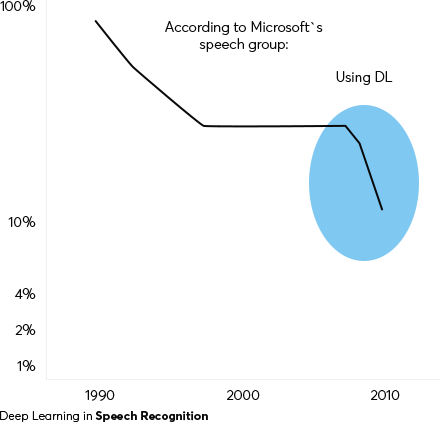
Speech is not a solved problem.
- All applications will have some errors.
- Key: design the system so some aspects are easy.
Many of the biggest problems facing humanity today, like curing diseases or addressing climate change, would be vastly easier to solve with the help of AI. At Convosense we believe that we can channel this revolutionary technology to radically improve human communications and collaboration.
By making human discourse fully machine readable we can open a vast landscape of business, education and consumer opportunities.
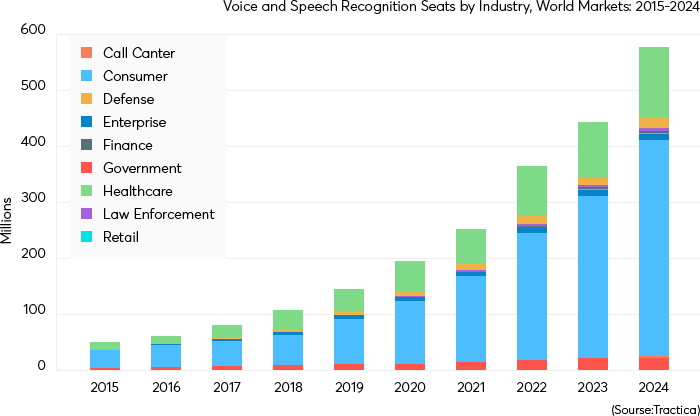
Starting from a base of $249 million in 2015, global speech and voice biometrics revenue will reach $5.1 billion by 2024, with cumulative revenue for the 10-year period totaling $19 billion at a compound annual growth rate (CAGR) of 40%. Enterprise growth markets are expected to include call centers, government IT, enterprise IT, and healthcare.